
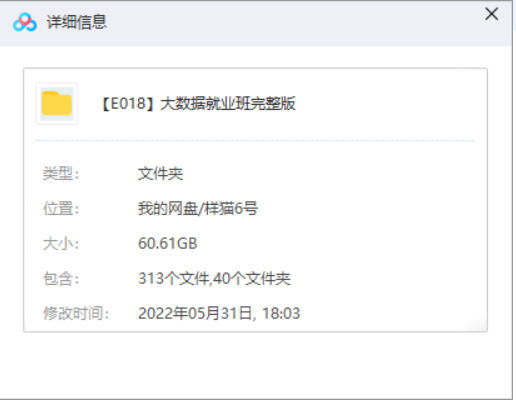
本资源为大数据(Big data)就业班完整版教学视频高清合集[AVI/FLV]百度云网盘下载,本次资源格式为AVI+FLV,做压缩包处理,避免资源丢失,请先保存下载再解压便可播放。

资源名称:大数据就业班完整版
合集数目:多部大合集
资源类型:技能学习
资源格式:AVI/FLV
资源大小:60.61GB
存储方式:百度云网盘
收藏网站:【好样猫资源】https://www.haoyangmao18.com/
大数据(big data),或称巨量资料,指的是所涉及的资料量规模巨大到无法透过主流软件工具,在合理时间内达到撷取、管理、处理、并整理成为帮助企业经营决策更积极目的的资讯。于“大数据”(Big data)研究机构Gartner给出了这样的定义。“大数据”是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力来适应海量、高增长率和多样化的信息资产。
麦肯锡全球研究所给出的定义是:一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合,具有海量的数据规模、快速的数据流转、多样的数据类型和价值密度低四大特征。
大数据技术的战略意义不在于掌握庞大的数据信息,而在于对这些含有意义的数据进行专业化处理。换而言之,如果把大数据比作一种产业,那么这种产业实现盈利的关键,在于提高对数据的“加工能力”,通过“加工”实现数据的“增值”。
从技术上看,大数据与云计算的关系就像一枚硬币的正反面一样密不可分。大数据必然无法用单台的计算机进行处理,必须采用分布式架构。它的特色在于对海量数据进行分布式数据挖掘。但它必须依托云计算的分布式处理、分布式数据库和云存储、虚拟化技术。
随着云时代的来临,大数据(Big data)也吸引了越来越多的关注。分析师团队认为,大数据(Big data)通常用来形容一个公司创造的大量非结构化数据和半结构化数据,这些数据在下载到关系型数据库用于分析时会花费过多时间和金钱。
大数据分析常和云计算联系到一起,因为实时的大型数据集分析需要像MapReduce一样的框架来向数十、数百或甚至数千的电脑分配工作。大数据需要特殊的技术,以有效地处理大量的容忍经过时间内的数据。适用于大数据的技术,包括大规模并行处理(MPP)数据库、数据挖掘、分布式文件系统、分布式数据库、云计算平台、互联网和可扩展的存储系统……
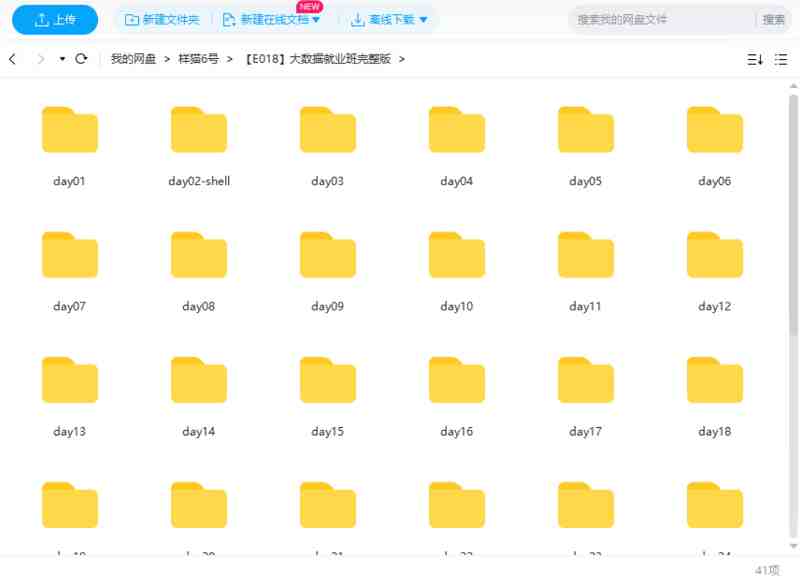
资源列表:
资料补漏.rar
课件代码资料.zip
课件代码资料.rar
解压密码.txt
day39.rar
day38.rar
day37.rar
day36.rar
day35.rar
day34.rar
day33.rar
day32.rar
day31.rar
day30.rar
day29.rar
day28.rar
day27.rar
day26.rar
day25.rar
day24.rar
day23.rar
day22.rar
day21.rar
day20.rar
day19.rar
day18.rar
day17.rar
day16.rar
day15.rar
day14.rar
day13.rar
day12.rar
day11.rar
day10.rar
day09.rar
day08.rar
day07.rar
day06.rar
day05.rar
day04.rar
day03.rar
day02.rar
day01.rar
day39
05.spark2.0介绍&netty rpc & echarts说明(待处理)_.avi
04.spark1.6的dataset讲解_.avi
03.spark on yarn的两种方式_.avi
02.面试题讲解2_.avi
01.面试题1_.avi
day38
05.sparkmllib代码实例_.avi
04.kmean算法&决策树算法&支持向量机算法简介_.avi
03.K近邻的一些应用&贝叶斯算法简介_.avi
02.K近邻算法代码讲解_.avi
01.numpy基本API简介&K近邻算法思想_.avi
day37
06.线性代数&&numpy简介(待处理)_.avi
05.sparkstreaming复习&概率统计知识_.avi
04.python语法补充&机器学习的一些基础知识_.avi
03.python控制结构&其他语法_.avi
02.广告平台精准推送系统解决方案(插播)_.avi
01.python环境安装&基本数据类型_.avi
day36
07.任务执行流程_.avi
06.DAG切分stage_.avi
05.stage的划分流程_.avi
04.任务提交流程_.avi
03.RDD的执行流程_.avi
02.Task序列化过程_.avi
01.Worker启动Executor过程_.avi
day35
06.spark源码解析—spark启动流程详解_.avi
05.spark源码解读—资源分配_.avi
04.spark源码解读—ClientActor提交任务_.avi
03.spark源码解读—任务提交流程_.avi
02.spark源码解读—sparkContext的创建_.avi
01.spark源码解读—actor通信回顾_.avi
day34
07.spark streaming整合elastic search_.avi
06.判断外挂的代码实现1_.avi
05.判断游戏外挂设计思路_.avi
04.其他游戏指标说明&&外挂分析_.avi
03.游戏用户留存率_.avi
02.游戏新增用户&&活跃用户_.avi
01.复习&&游戏指标介绍_.avi
day33
06.elasticsearch简介&&整合kafka_.avi
05.游戏项目—logstash采集日志到kafka_.avi
04.游戏项目—日志采集分析_.avi
03.游戏项目—架构分析2_.avi
02.游戏项目—架构分析_.avi
01.复习&&游戏项目–游戏体验_.avi
day32
06.spark streaming和kafka整合的两种方式&&窗口函数讲解_.avi
05.kafka复习&&sparkstreaming整合kafka_.avi
04.spark streaming整合flume_.avi
03.spark streaming数据累加案例_.avi
02.spark Streaming例子编写_.avi
01.复习&&spark stream简介(待处理)_.avi
day31
06.spark的远程debug_.avi
05.spark的dataframe&&与hive整合_.avi
04.sparkSQL介绍_.avi
03.spark中stage、依赖的划分_.avi
02.spark任务提交流程_.avi
01.复习&&RDD的checkpoint机制_.avi
day30
06.spark任务提交流程&&RDD缓存机制_.avi
05.wordcount执行流程_.avi
04.spark操作数据库API_.avi
03.IP归属地查找_.avi
02.自定义排序&&IP查找_.avi
01.复习&&分区实现_.avi
day29
06.网站访问次数实现_.avi
05.计算用户在小区停留时间最长的两个小区_.avi
04.rdd高级算子讲解3_.avi
03.rdd高级算子讲解2_.avi
02.rdd高级算子讲解1_.avi
01.复习_.avi
day28
06.spark算子操作&&JavaAPI实现wordcount_.avi
05.spark算子介绍_.avi
04.spark集群安装介绍_.avi
03.spark介绍_.avi
02.隐式转换2_.avi
01.复习&&隐式转换(待处理)_.avi
day27
06.隐式转换_.avi
05.自定义RPC框架2&&柯理化_.avi
04.自定义RPC框架1_.avi
03.RPC通信_.avi
02.使用akka实现一个简单的RPC框架_.avi
01.复习&&akka介绍_.avi
day26
06.Java线程池回顾_.avi
05.用actor实现单机版的wordcount_.avi
04.样本类&&模式匹配&&actor_.avi
03.面向对象3–trait_.avi
02.面向对象2–object_.avi
01.复习&&面向对象1_.avi
day25
06.scala单机版wordcount实现_.avi
05.scala元组、映射_.avi
04.scala数组_.avi
03.scala函数式编程_.avi
02.scala基础语法_.avi
01.scala介绍&&环境准备_.avi
day24
08.汽车之家用户画像_.avi
07.推荐系统的代码梳理_.avi
06.推荐系统需求分析_.avi
05.mahout推荐系统代码介绍_.avi
04.推荐系统中mahout介绍_.avi
03.推荐系统算法介绍2_.avi
02.推荐系统的算法介绍_.avi
01.推荐系统了解_.avi
day23
07.交易风控系统架构&&代码分析_.avi
06.交易风控系统业务分析_.avi
05.点击流日志分析代码讲解_.avi
04.点击流日志数据模型分析_.avi
03.点击流日志业务分析2_.avi
02.点击流日志业务分析_.avi
01.点击流日志分析1_.avi
day22
05.redis的一些建议优化_.avi
04.实时计算的一些常见问题总结_.avi
03.日志监控系统代码讲解1_.avi
02.日志监控系统业务分析2_.avi
01.日志监控系统业务分析_.avi
day21
08.redis各种数据结构的操作及其案例_.avi
07.redis基础知识介绍_.avi
06.订单实时处理代码实现_.avi
05.订单实时处理业务分析_.avi
04.kafka整合storm程序调试_.avi
03.代码编写_.avi
02.flume+kafka整合_.avi
01.复习&&kafka配置文件讲解_.avi
day20
07.kafka内部细节讲解_.avi
06.kafka API1_.avi
05.kafka集群安装&&常见问题分析_.avi
04.提问&&kafka中的几个概念讲解_.avi
03.kafka基础知识_.avi
02.ack机制补充&&代码跟踪_.avi
01.复习&&自己实现storm流程分析_.avi
day19
06.storm消息容错机制_.avi
05.storm内部通信机制2_.avi
04.storm内部通信机制1_.avi
03.storm集群任务提交流程2_.avi
02.storm集群任务提交流程1_.avi
01.storm提问&&昨天的知识回顾_.avi
day18
05.storm wordcount流程分析_.avi
04.storm wordcount案例分析&&代码编写_.avi
03.storm集群部署&&任务提交部署讲解_.avi
02.storm核心组件和架构_.avi
01.课程介绍&&实时计算的应用场景_.avi
day17
04.云笔记项目4_.avi
03.云笔记项目3_.avi
02.云笔记项目2_.avi
01.云笔记项目1_.avi
day16
06.使用MR操作HBASE_.avi
05.HBASE原理_.avi
04.JavaAPI操作HBASE2_.avi
03.JavaAPI操作HBASE_.avi
02.HBASE安装以及常用shell命令_.avi
01.HBASE简介(待处理)_.avi
day15
06.Kmeans算法思想_.avi
05.贝叶斯算法&&KNN算法思想讲解_.avi
04.项目讲解4_.avi
03.项目讲解3_.avi
02.项目讲解2_.avi
01.项目讲解1_.avi
day14
05.项目讲解5–瞎扯_.avi
04.项目讲解4_.avi
03.项目讲解3_.avi
02.项目讲解2_.avi
01.项目讲解1_.avi
day13
06.点击流数据项目背景分析_.avi
05.sqoop导入导出数据&&网站点击流分析_.avi
04.azkaban提交各种示例&&sqoop安装使用_.avi
03.azkaban示例演示_.avi
02.flume多个agent连接&&azkaban介绍_.avi
01.hive复习&&flume使用_.avi
day12
06.flume初体验_.avi
05.hive中复杂sql面试题讲解_.avi
04.hive自定义函数&&transform的使用_.avi
03.广告推送项目整体架构_.avi
02.hive中的sql讲解,重点是join操作_.avi
01.hive中分桶的机制和作用_.avi
day11
06.hive的基本命令练习_.avi
05.hive安装及初体验_.avi
04.HA联邦机制&&hive的实现机制_.avi
03.HA集群搭建_.avi
02.HA配置文件讲解_.avi
01.HA机制以及设计思路的分析_.avi
day10
06.自定义inputformat&&MR其他注意事项_.avi
05.运营商流量日志增强—自定义outputformat_.avi
04.使用groupingcomparator求同一订单中最大金额的订单(待处理)_.avi
03.找出QQ共同好友的实现_.avi
02.map端join实现&&倒排索引实现_.avi
01.复习&&解决数据倾斜的思路分析_.avi
day09
06.编写类似join功能的MR程序_.avi
05.在windows下使用eclipse提交MR到集群运行的原理和配置_.avi
04.MR运行在yarn集群流程分析&&本地模式调试MR程序_.avi
03.Combiner的用途以及文件切片大小的处理_.avi
02.MR内部的shuffle过程详解_.avi
01.复习&&流量汇总排序的mr实现_.avi
day08
06.自定义partitionner_.avi
05.客户端提交job流程之源码跟踪_.avi
04.mr实现流量统计&&文件切片的原理_.avi
03.wordcount程序运行流程分析_.avi
02.wordcount程序原理及代码实现_.avi
01.复习&&mapreduce的核心思想_.avi
day07
06.源码跟踪初探&&shell脚本采集日志上传到HDFS_.avi
05.hadoop中的RPC框架演示_.avi
04.JAVA客户端流式操作HDFS_.avi
03.namenode管理元数据的机制2_.avi
02.namenode管理元数据的机制_.avi
01.客户端向HDFS写数据的流程_.avi
day06
06使用JavaAPI操作HDFS文件系统_.avi
05hadoop shell命令操作_.avi
04hadoop集群安装_.avi
03hadoop安装环境准备_.avi
02hadoop在实际项目中的架构分析_.avi
01hadoop生态圈介绍及就业前景_.avi
day05
11.jvm入门_.flv
10.rpc框架的联调测试_.flv
09.rpc框架的客户端设计思路_.flv
07.rpc服务端的完整实现流程_.flv
06.rpc框架的服务端设计思路_.flv
05.spring的初始化机制及自定义注解的实现方式_.flv
04.高性能nio框架netty_.flv
03.nio的原理和示例代码_.flv
02.自定义rpc框架的设计思路_.flv
01.关于socket流阻塞的含义和wait-notify的用法_.flv
day04
17.利用socket来进行远程过程调用_.flv
16.动态代理的demo代码_.flv
15.动态代理的工作机制_.flv
14.java的反射实现api_.flv
13.activemq_.flv
12.activemq_.flv
11.关于并发编程的一些总结_.flv
10.volatile的工作机制代码测试_.flv
09.blockingqueue的功能和使用示例_.flv
08.并发包中各种线程池的用法及future获取任务返回结果的机制_.flv
07.java并发包中的线程池种类及特性介绍_.flv
06.lock和synchronized的一些区别和选择考虑因素_.flv
05.reentrantlok的方法示例_.flv
04.synchronized同步代码块示例_.flv
03.线程实现的两种方式_.flv
02.内容大纲介绍_.flv
01.关于zk客户端连接失败的问题_.flv
day03
13.分布式共享锁的程序逻辑流程_.flv
12.分布式应用系统程序效果测试_.flv
11.zookeeper客户端线程的属性–守护线程_.flv
10.分布式应用系统服务器上下线动态感知程序开发_.flv
09.zookeeper的java客户端api2_.flv
08.zookeeper的java客户端api_.flv
07.zookeeper集群自动启动脚本及export变量作用域的解析_.flv
06.zookeeper的命令行客户端及znode数据结构类型监听等功能_.flv
05.zookeeper集群的搭建_.flv
04.zookeeper的集群角色分配原理_.flv
03.zookeeper的功能和应用场景_.flv
02.自动化部署脚本_.flv
01.关于yum网络版仓库和scp命令缺失的问题_.flv
day02-shell
13.nginx和keepalived部署安装的流程解析_.flv
12.高并发网站架构_.flv
11.高级文本处理命令之awk_.flv
10.高级文本处理命令之sed_.flv
09.高级文本处理命令之cut-sort-wc_.flv
08.高级文本处理命令的引入_.flv
07.shell编程的基本语法_.flv
06.shell编程的变量定义_.flv
05.iptables的常用操作_.flv
04.jdk-mysql-tomcat-yum本地源_.flv
03.压缩解压缩–jdk安装_.flv
02.查看文件内容–系统服务管理–系统启动级别_.flv
01.关于crt中文乱码问题–虚拟机克隆后网卡问题_.flv
day01
11.ssh免密登陆配置.avi
10.常用系统操作命令.avi
09.文件权限的操作.avi
08.文件常用操作命令.avi
07.回顾上午的ip地址配置.avi
06.linux网络配置及CRT远程连接.avi
05.vmware虚拟网络的配置介绍.avi
04.局域网工作机制和网络地址配置.avi
03.linux图形界面及文件系统结构介绍.avi
02.linux系统安装过程.avi
01.基础部分课程介绍.avi

